 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDavid Elworthy
Retrieval from Captioned Image Databases Using Natural Language Processing
Nov 20, 2000
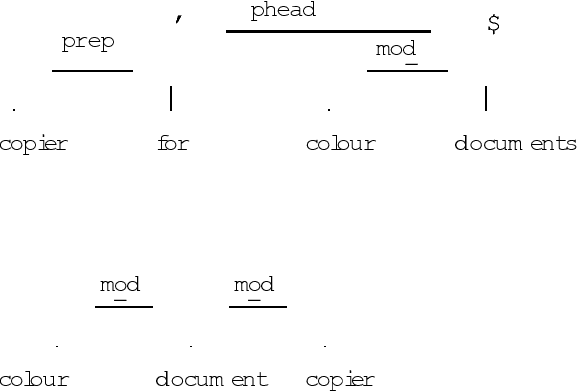


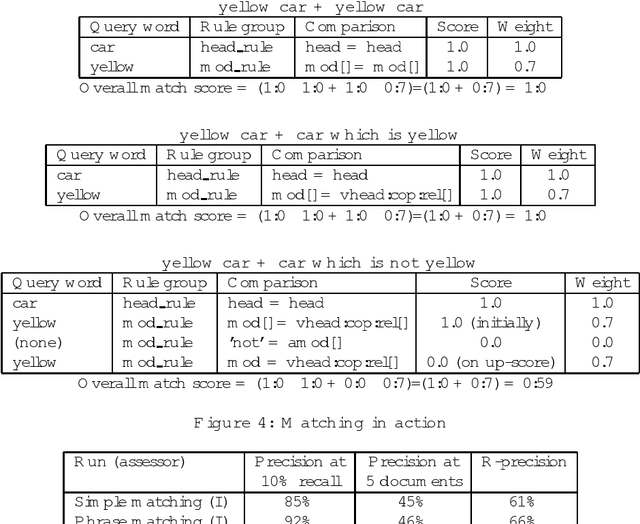
It might appear that natural language processing should improve the accuracy of information retrieval systems, by making available a more detailed analysis of queries and documents. Although past results appear to show that this is not so, if the focus is shifted to short phrases rather than full documents, the situation becomes somewhat different. The ANVIL system uses a natural language technique to obtain high accuracy retrieval of images which have been annotated with a descriptive textual caption. The natural language techniques also allow additional contextual information to be derived from the relation between the query and the caption, which can help users to understand the overall collection of retrieval results. The techniques have been successfully used in a information retrieval system which forms both a testbed for research and the basis of a commercial system.
Language Identification With Confidence Limits
Jul 07, 1999
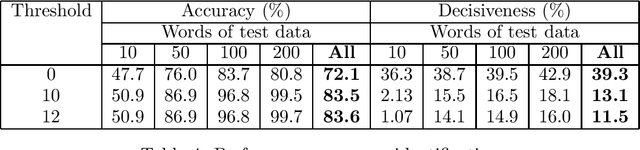
A statistical classification algorithm and its application to language identification from noisy input are described. The main innovation is to compute confidence limits on the classification, so that the algorithm terminates when enough evidence to make a clear decision has been made, and so avoiding problems with categories that have similar characteristics. A second application, to genre identification, is briefly examined. The results show that some of the problems of other language identification techniques can be avoided, and illustrate a more important point: that a statistical language process can be used to provide feedback about its own success rate.
Tagset Design and Inflected Languages
Apr 04, 1995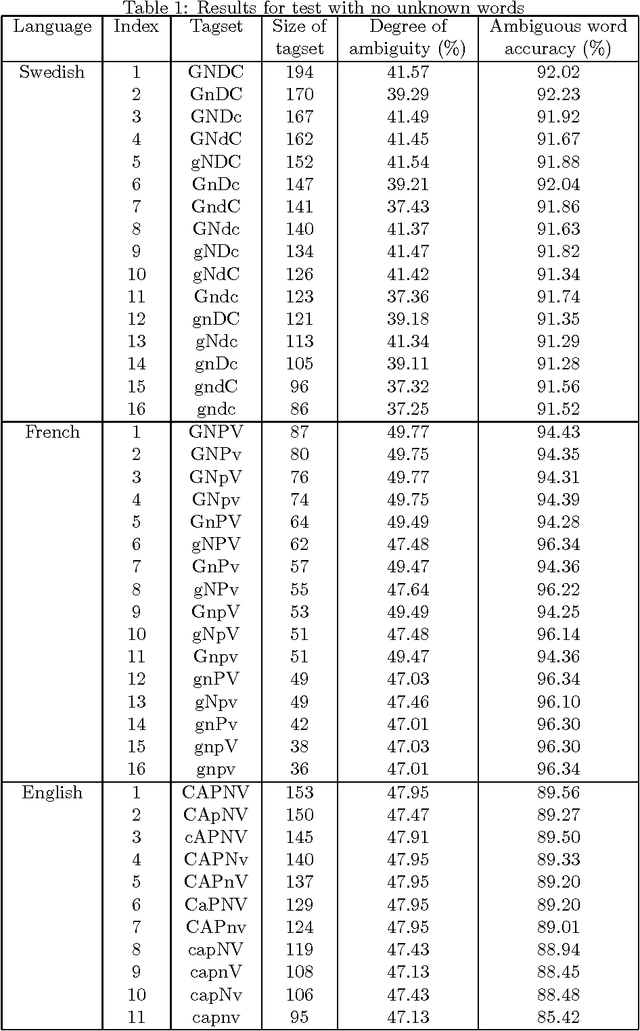
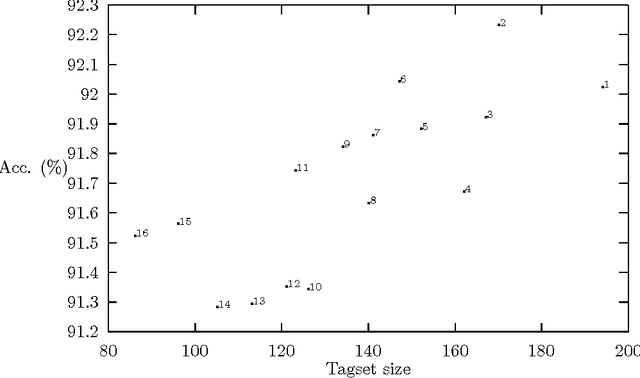
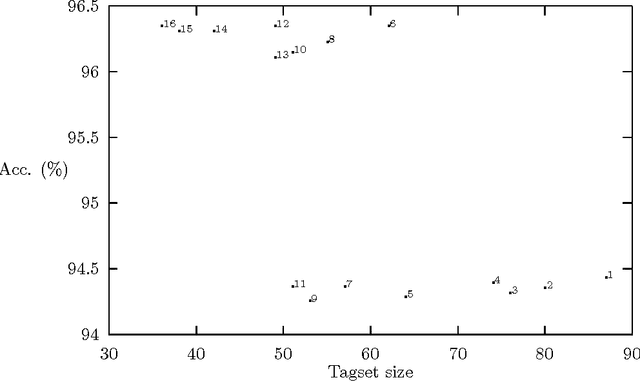
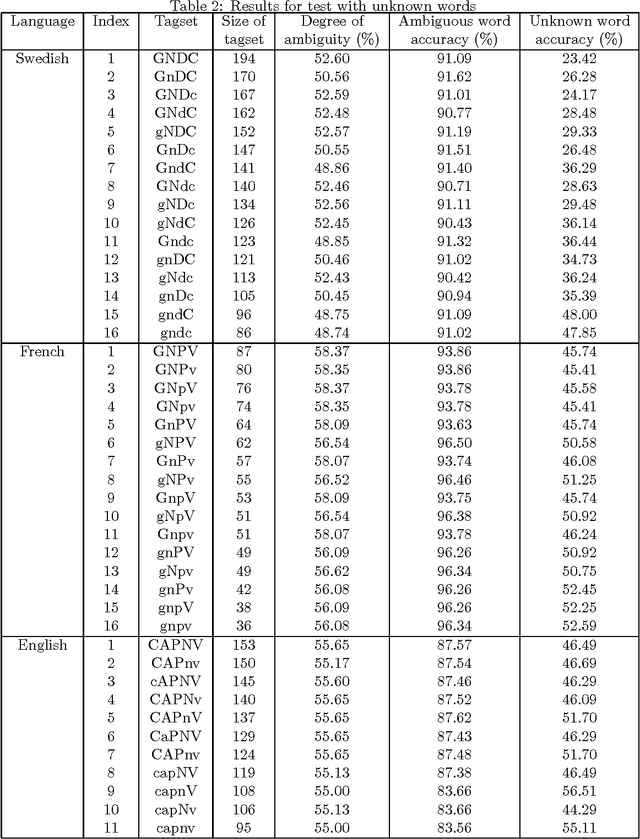
An experiment designed to explore the relationship between tagging accuracy and the nature of the tagset is described, using corpora in English, French and Swedish. In particular, the question of internal versus external criteria for tagset design is considered, with the general conclusion that external (linguistic) criteria should be followed. Some problems associated with tagging unknown words in inflected languages are briefly considered.
Does Baum-Welch Re-estimation Help Taggers?
Oct 24, 1994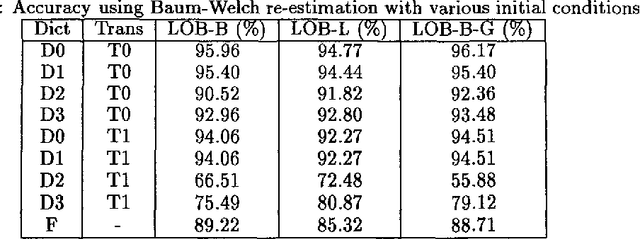
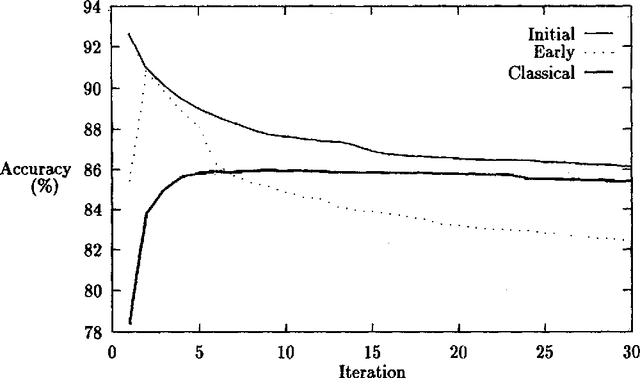

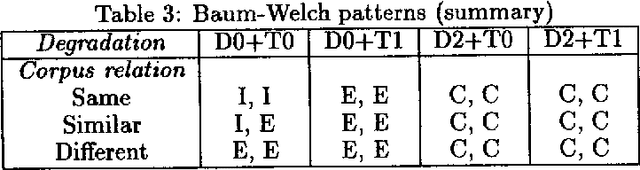
In part of speech tagging by Hidden Markov Model, a statistical model is used to assign grammatical categories to words in a text. Early work in the field relied on a corpus which had been tagged by a human annotator to train the model. More recently, Cutting {\it et al.} (1992) suggest that training can be achieved with a minimal lexicon and a limited amount of {\em a priori} information about probabilities, by using Baum-Welch re-estimation to automatically refine the model. In this paper, I report two experiments designed to determine how much manual training information is needed. The first experiment suggests that initial biasing of either lexical or transition probabilities is essential to achieve a good accuracy. The second experiment reveals that there are three distinct patterns of Baum-Welch re-estimation. In two of the patterns, the re-estimation ultimately reduces the accuracy of the tagging rather than improving it. The pattern which is applicable can be predicted from the quality of the initial model and the similarity between the tagged training corpus (if any) and the corpus to be tagged. Heuristics for deciding how to use re-estimation in an effective manner are given. The conclusions are broadly in agreement with those of Merialdo (1994), but give greater detail about the contributions of different parts of the model.
Automatic Error Detection in Part of Speech Tagging
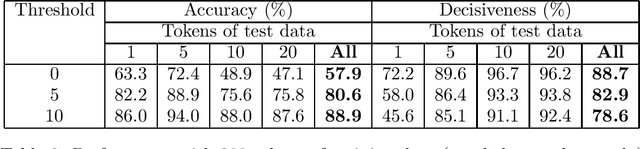
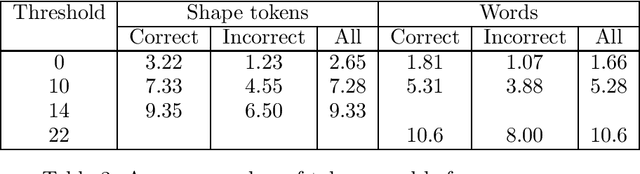
Oct 21, 1994A technique for detecting errors made by Hidden Markov Model taggers is described, based on comparing observable values of the tagging process with a threshold. The resulting approach allows the accuracy of the tagger to be improved by accepting a lower efficiency, defined as the proportion of words which are tagged. Empirical observations are presented which demonstrate the validity of the technique and suggest how to choose an appropriate threshold.